


Is Artificial Intelligence increasing our Carbon Footprint?
Technology


The artificial-intelligence industry is often compared to the oil industry: once mined and refined, data, like oil, can be a highly lucrative commodity. Now it seems the metaphor may extend even further. Like its fossil fuel counterpart, the process of deep learning has an outsize environmental impact.
Computational limits have dogged neural networks from their earliest incarnation — the perceptron — in the 1950s. As computing power exploded, and the internet unleashed a tsunami of data, they evolved into powerful engines for pattern recognition and prediction. But at what cost?
Modern AI models consume a massive amount of energy, and these energy requirements are growing at a breathtaking rate. In the deep learning era, the computational resources needed to produce a best-in-class AI model has on average doubled every 3.4 months; this translates to a 300,000x increase between 2012 and 2018.
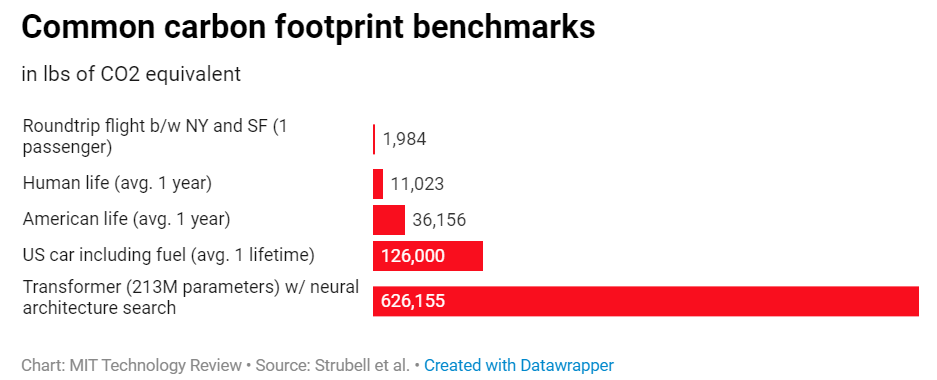
Training a single AI model can emit as much carbon as five cars in their lifetimes. It’s hard to believe, isn’t it? But have a look at this:
What’s causing it?
Data collected increasing in an exponential manner
Cost of computing decreasing as the technology advances
More complex algorithms developed each day
Researchers across the world pay very less attention to the efficiency and do extensive experimentation leading to redundant computations
How to avoid it?
Efficient hyperparameter* tuning of models instead of using brute force method
Transparency and measurement of the issue- present energy consumed along with the results or estimated carbon emissions to train and use the model
Avoid redundant computing
*Hyperparameter tuning: choosing a set of optimal hyperparameters for a learning algorithm

Like what you read? Share this article with your friends and follow us on:
Instagram| Medium| Facebook